
CD���̵����ݽṹ
����˵��CD������������Ϣ����ʷ�ϵ�һ����Ҫ��ͻ�ơ�CD������1982��10�·ݵ�������Ȼ����Ѿ���20�������ʷ���������������ڽ��쿴�������Ƿdz��Ƚ��ģ�������������Ȼ��ʢ����ʹ����DVD����ʢ�еĽ��죬Ҳ����Ҫ���������壨ý�飩��
Ҫ���˽�CD���̵ľ���ԭ�����Ͳ��ܲ����˽�CD���̵����ݽṹ��ȷ�е�˵����CD���������ݵı���ԭ���������������˵�ʱ���Ƚ��ı��뼼����DVD��֮��ȣ�Ҳ��û�б��ʵı仯��
CD��������IJ�Ʒ��CD-Audio���似���淶����Ϊ��Ƥ�飨Red Book)��Ӧ���ڳ�Ƭ�������Լ�ʹ�����պ��������չ�淶��Ҳ��������Ϊ�����ƶ��ġ�CD���̵Ĺ淶��ҵ���Բ�ͬ��ɫ��Book�����֣�Ŀǰ�������¼��֣�

����֮�⣬���������ӻ�Ƥ�����Ƥ����չ�����Ĺ淶�����Ƿֱ���Multisession CD��Photo CD������������֣�CD�ķ����ߣ���û�и����ǵ����涨��ɫ��
��CD�����У����ݵ���С�Ŀɷ��ʴ洢��λ��Block���飩����CD-ROM�淶�����֮ΪSector(����������Red Book�淶�й涨�����������ɸ��ӿ���ɣ�����ӿ���DZȽ����������֡��Frame)��ʲô��֡�أ����ǿ�������ΪCD���̱���ĵ�λ������������CD���̵���������ͼ�У����ǿ����˽�֡���Ĺ�ϵ���

CD���̵��������̣���CD-AudioΪ��������Ŵ�
�������ڿ��Է����������CD-Audio�����ݽṹ�����ԭ��������CD-Audio��Ϊ��������������ÿ��������ȡ������Ϊ16bit��ȡ��Ƶ��Ϊ44.1KHz��Ҳ����˵ÿ��ȡ��44100�Ρ�CD-Audio�涨��ÿһ��������ȡ�Ŀ���Ϊ75����ÿ�����ְ���98��֡����ô��������̯�����Ƕ����أ�44100��75��98=6��Ҳ����˵ÿһ֡��ȡ������Ϊ6�Σ�ÿ������������ÿ������ȡ������Ϊ16bit�����һ֡����������6��2��16=192bit=24�ֽڡ������һ֡����Ϊʲô��24�ֽڵ���������ע��ͼ�к�Ȧ�IJ��֣��Ǿ��Ǿ���CD���̾�������Ҫ���֣�Ҳ�������������ؽ��ܵ����ݣ���
��������֪����CD����һ�������������2352�ֽڣ���Ҳ������CD�淶��ͨ�ÿ����������ǣ��������ֵ�CD-ROM�淶�����������ڲ���ƽ����˸��ģ�

CD-ROM�ļ���������ʽ������Ŵ�Mode 1�������dz��õ�CD-ROM�������ݹ��̵ĸ�ʽ��Mode 2����CD-I��VCD��CD-ROM XA�ȹ��̵ĸ�ʽ������Form 1Ҳ�ǵ������ݹ��̸�ʽ��������ECC��������Ĵ�������룬EDCΪ�������루CRCУ�飩
ע�⣬��ͼֻ���������飩�ĸ�ʽͼ����Ҫ�����������CD��������ͼŪ���ˣ�������ECC���֣���ͼ1�еġ�У�顱�������£���һ�����ǽ������Ļ��һ��������
CD���̵ı���������
CD����ʹ�������ֱ������ֱ�֤���̵Ŀ�¼������һ���Ǵ���Ϣ������ȷ���ϱ�֤��һ���Ǵ�������¼��ͨ�������ʶ��ɿ����ϱ�֤�����Ƿֱ���CIRC������EFM���Ʊ��롣
CIRC��ȫ���ǽ��潻������-�����ű��루Cross Interleaved Read-Solomon Code����������ּ�dz������Ӷ�ά���������⣬����Դ���ݴ�ɢ������һ���Ĺ��������Ƶ�ͽ������룬ʹ��������潻�����Ӷ���һ����߾�������������Ϊ����һ���û����ݵĴ����������������������������ľ���������
������������������������CD��������ͼ������Ŵ�ͼ�еı�ž���CD��¼ʱ���������ɵĹ��̡�
��һ����������һ��֡��ԭʼ���ݣ�24�ֽڣ����ǿ��Գ�֮Ϊ��ʼ֡������ر������Frame-1�����F1��
�ڶ������Ǽ���CIRC���룬һ��8���ֽڣ����ǿ��Գ�֮ΪУ��֡������ر������Frame-2�����F2�������ֽ���Ϊ32�������dz�˵�ģ���ν��C1��C2�������������һ�μӽ�ȥ�ģ�C1��C2��C����CIRC�������д��
���������Ǽ�������룬һ���ֽڣ����ǿ��Գ�֮Ϊ����֡������ر������Frame-3�����F3������ʱ֡������Ϊ33�ֽڡ�
֮��ÿ��F3֡�ټ���3���ֽڵ�ͬ����Ϣ��ͳ�Ϊ���������ڿ�¼��֡��������Ϊ36�ֽڡ����EFM���ƣ�����������ÿ�ֽ�8bitת����ÿ�ֽ�17 bit�ķ�ʽ�������յ��ŵ����壨Channel bit���Կ��ƿ�¼����Ŀ���ء�
ʲô��EFM�����أ�����Eight to Fourteen Modulation����д����8��14���ơ�Ϊʲô��ʹ�������ı����Դ���ݽ��С��ġ��أ��Ҫ�ӹ��̵Ķ�ȡԭ��˵��

�����ϵİ�����ƽ�沢��ֱ�Ӵ���0��1
���̵Ķ�ȡ�Ǹ��ݷ��伤���ǿ����������1��0�ķֱ棬�����ⷴ�书�ʵ�ǿ��������ֱ�Ӵ���1��0�����书��ǿ����ͻ��㣬Ҳ���Ƿ����ƽ�ķ�ת�㣬�����ж�Ϊ��ֵ1����ʱ��İ�����ƽ��������ֵ0��
����һ���������������1����ô����ζ�Ű�����ƽ��Ҫͻ���Σ���ռ�ø���Ŀ�¼�ռ䣬�Ӷ���Ӱ����Ч�������ݻ�������˵����Ϣ�����������Ե�ƽ�ĸߵ�������1��0�����������0��1�ܳ����ֺ����ж��ж��ٸ�1��0��0��1��ת��Ҳ���ѷֱ棬���Ա���Ҫ����һ���Ĺ������ơ����������Խ���ij�ֱ��뷽ʽ����ֹ������1���������ܰ�������0�ij���������ij�ַ�Χ֮��������ʶ���������ν�ġ��γ����ƣ�RLL��Run Length Limited���������
EFM����������һ��ר������Ϣ��¼���ŵ����Ʊ��룬����ԭʼ�������½��б��ţ��Ա�֤������������1���֣���������0������2��10��֮�䣬���Ա�ʾΪRLL��2,10)��Ҳ����˵�������ϵ���Ϣ�У�������1֮�䣬���������10��0������Ҫ����������0��������������Ӧ�Ĺ���������ʱ�Ӽ�ʱ��Ϣ��ÿ���ŵ������ʱ�䳤�ȣ����Ϳ���ȷ�ķֱ�������ˡ���Ҫָ�����ǣ���8bit�������±��14bit���ݺ�����14bit����֮����Ҫ����RLL��2��10����Ҫ����˻�Ҫ��������14bit������������3bit�ĺϲ��루Merging bit�����Ӷ�ʹ���յı��볤�ȱ�Ϊ17bit��
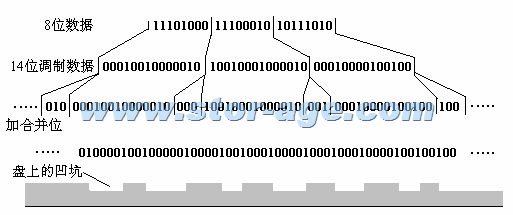
EFM���Ʊ���ʾ��ͼ��Ϊ�˱�֤����14λ����֮���Է���RLL��2��10����Ҫ���ּ�����3λ�ϲ��룬���EFM��ʵ��8��17����
�˽���CIRC��EFM��CD���ݿ�¼�е����ã��Ͳ���������֮��ص�CD��¼�������ĺ��壬�������Ǿͽ���������й�CD���̵�C1��C2�����������������EFM��صľ������dz��������������֡������۵�Jitter�����ڱ�ר�������½���ϸ������
CIRC��������
�����Ѿ�������ÿ��24�ֽڵ�ԭʼ����֡��Ҫ������8�ֽڵ�У�����Ա�֤֡���ݵĿɿ��ԣ������У�������Ϊ�������������ɣ����������忴һ�¡�
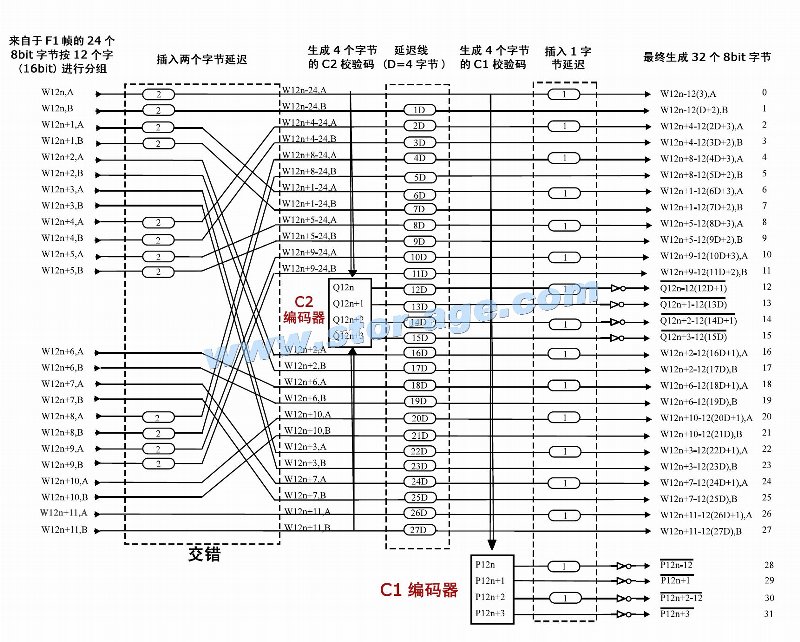
CIRC��������ͼ������Ŵ�ͼ����W12�������һ��F1֡��12���֣�16bit����n����F1֡�ı�ţ�A��B�������һ���ֵ������ֽڣ�8bit��
��һ�������潻��������C2У����
�ڽ���CD�������ɹ��̵�ʱ������֪��CIRC���봦��F2���ɽΣ����Ҫ�ȵ���F1ԭʼ����֡��Ҳ����24�ֽڡ�Ҫ֪����֮���Գ�ΪCIRC���룬����Ϊ�ڱ���Ĺ����У�Դ�����н���ͽ����Ĺ��̡����ȣ�Դ����Ҫ�������֣�ͼ�е�A��B��һ��ֳ�6�����飬ż������������ֽڵ��ӳ٣��Ӷ��γ���Ƶ�������롣
����Ҫ����һ����ν���ӳ٣������ֽڵ��ӳ���ζ���ӳ���֡��Ҳ����˵�������н���֮��ż�����Ѿ�������ԭ��F1֡�е�Դ���ݣ����ǵ�ǰ֡��ǰ��֡�е�ż�������ݣ������ǰ��֡����ǰ֡����ζ�������ֽڵ��ӳ٣���ԭʼ��ż���齫�ں���֡�Ľ��������г��֡����⣬��ͼ�п��Կ������ֵ�˳���ڽ��������˺ܴ�ͬ������ǰ��֡���ݽ��沢��˳���Ĺ��̾�����Ƶ�������롣
�˺���Ƶ���������ɵ������ݽ���C2����������QУ���롣QУ����Ϊ4�ֽڣ�������ɵ�������Ϊ28�ֽڣ����C2Ҳ����Ϊ��28��24�����룬��˼��ָ����24���ֽڣ����28���ֽڡ�
�ɴ˿ɼ���C2���벢�����ԭʼF1֡�����ݽ��У���ΪʲôҪ������˸��ӵĽ��潻���ı����أ�����Ϊ�˱�֤����Ч�ʶ���ƣ����Ľ��и���ϸ�Ľ�����
�ڶ������ֽ������ӳ�4֡������C1����
��C2������ɺ����д��ģ���ֽ��ӳٽ������룬ִ����������ľ����ӳ��ߣ��ӳٵ�λΪ4�ֽڣ�Ҳ����˵4֡��������λ��ÿ�����еĵ����ֽڡ����Ҫ��ô�����أ��ȷ�˵��C2�����ĵĵ�һ���ֽڲ��ӳ٣��ڶ����ֽ����Ӻ�4֡�������ֽڽ��Ӻ�8֡������˷���ֱ����28���ֽڣ������Ӻ�108֡��Ҳ����˵��C2������28���ֽڣ������й��ɵķ�ɢ��109��֡�У���һ���ֽ��Ӻ�0֡���������һ���ֽ��Ӻ�108֡��һ����109֡����
�ӳٲ���֮���������C1����������Ȼ��ʱ��������ԭʼ��F1֡���ݲ������ˣ�C1����������28���ֽڵĻ�����������4���ֽڵ�PУ���룬�Ӷ�����˽�����F2֡�IJ�������������28���ֽڣ����32���ֽڣ����C1Ҳ����Ϊ��32��28�����롣����������в��ѿ�����C1����Ķ����а�����C2���루��Ȼ�ǽ����Ӻ�ģ���Ҳ�е��˶�QУ������б���������
���ڵ�F2֡�Ѿ���F1֡���˺ܴ�ͬ�����֡���Ϊn����ôF2-n֡��ֻ��һ���ֽ�������F1-n֡�����ԣ��ϸ�Ľ���C1��C2�����Ƕ�F1֡��У����룬��Ϊ��C2���뿪ʼ��������Ѿ�������F1֡�е�ԭʼ���ݡ����������潻������Ŀ�ľ����ڷ�ֹһ֡�г������������Ĵ���������������ԭԭ�����ذ�ԭʼF1����C2���롪��C1����Ĺ�������У���룬���Ƿdz������ģ������һ֡��24���ֽ��г������������Ĵ����룬��ƾCIRC����ƣ�����������Ȼ���ޡ�����Դ���ݷ�ɢ����ͬ������֡�У�Ȼ���ٽ���У�飬������ṩ��������֡�ľ��������������ϼ�ʹ24���ֽ�ԭʼ����ȫ�����⣬������ÿ���ֽ����շֲ��ڼ��Ϊ4��28��֡�����Ϊ109֡���У�Ҳ�п��ܱ���ȫ������Ȼ����������н��潻���Ļ������ֿ������Dz�����ڵġ�
C1��C2�������
�������������˽���CD���̵�CIRC�������֮�Ͳ�������CD�Ľ�����̣���������̾��漰���˾�����������Ч�������ֿ�¼������������˵���������Ķ���������

CD�����е�C1��C2��������ͼ������Ŵ�
�ڽ���ʱ����ʵ����CIRC����ķ����̣�ԭ��C2�ȱ��룬������C1�Ƚ��룬ԭ���ӳٵģ�����ʱ���ӳ٣���ԭ�Ȳ��ӳٵ������ݹ�������ӳ��Է����潻���������ݻ�ԭ��
������ͼ�У����ǿ��Է��֣�C1��C2�����DZؾ��Ĺ��̣���������ijЩ��������˵�ģ�C1Ӧ�����˵Ĵ���Żύ��C2���롣��ʵ�ϣ�����C1�����������û�д���ҪC2���롣�ӱ�������У����ǿ���֪��������������Ķ�����ȫ��ͬ����Ҳ��ΪʲôC1�������˵Ĵ���C2�����ܾ�������ʵ���������������������˵C2�ľ��������C1�ߡ�
�Թ�������C1��C2�ľ��������������أ����ҵ��ʹ���˴���ȼ�����C1��C2��������˹涨���ɼ�дΪEn1��En2������E����Error������n�������ִ���Ĵ�����1����һ��C1������̣�2����һ��C2������̡�
�����һ��C1�����У�������һ�������ֽڣ���ΪE11��������������������ֽڼ�ΪE21���������3�������Ĵ����ֽڼ�ΪE31�����У�E11��E21��������C1�ξ�������E31���С����ǣ���Ҫ�����ӳٽ�������ƣ���ǰ֡��F2���Ĵ����ֽ��Ƿ�ɢ�ڿ��Ϊ109֡��28��֡�У��������ӳٺ���Щ������ֽڿ϶���������ͬһ֡���ˣ�����ͨ��C2������Ȼ�п��ܱ���������ʱ�������һ��C2�����У�������һ�������ֽڣ���ΪE12��������������������ֽڼ�ΪE22�����������3�������Ĵ����ֽڣ���ΪE32����E31һ����E32Ҳ������C2������̱�����������C2�����һ��CIRC������������E32�ij��־���ζ�ų�����һ���������Ĵ���֡��������ֳ�ΪCU��C-Uncorrectable����������������CD��˵��CU�Ǿ���Ҫ����������ֵġ�
��CD����ϵͳ�У�ר��ΪC1��C2������״̬��ǣ�Flag����ͨ�����Ǽ���֪����ǰ�ľ���״̬��
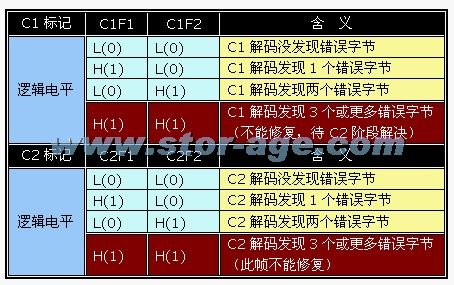
ͨ��4��C1��C2״̬�������ʾ����״̬��
�й�CD���̾�����ҵ���
��ҵ����У���û�ж�C2����ˮƽ������ȷ�涨�����Ǹ���Ķ�C1�����ʽ���������������Ϊ���C2����϶�����C1���������C1�������û���C2����
��CD-ROM�Ĺ淶�й涨���������ı��ǣ�ÿ10���ӳ���C1����Ĵ���E11��E21��E31��֡��������3%�����ǿ�����һ�£���һ����1���ȡ75��������ÿ����98��֡���㣬10�����ﹲ��10��75��98=73500��֡��3%����2205��֡��ԼΪƽ��һ��220��֡������һ����֡����ζ��һ�����飨�����������Ҳ������Ϊ������ʣ�BLER��BLock Error Rate��Ϊÿ��220�������ǿ�������Ϊ1����C1������ܺϣ�E11+E21+E31�����ܳ���220����
����������ͻ���Դ���CD-ROM�淶�й涨������C1����ʱ����E31������Ϊ��������֡������������C1�����������֡Ҫ����7����
������Ҫָ�����ǣ�BLER����������Щ���ǿ��Ա����ģ���Щ���Dz��ܱ����ģ���Ϊ��������E31��һC1���������������Ĵ������Ե͵�BLER������˵�����������ĺû�������һ�Ź��̵�BLER=210����û��E31������һ�Ź��̵�BLER=50����ȫ��E31������ô��ȫ����˵���ߵ���������ǰ�ߣ���Ȼ����BLER���ͣ�������E32��������
С��ʶ������CD���̵�C3����
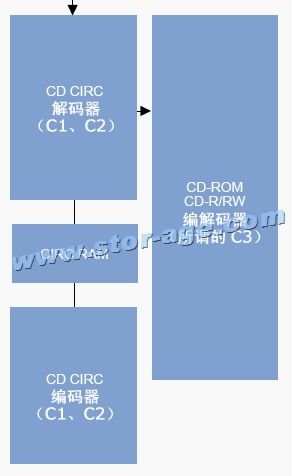
�������У������Ѿ�����CD�����ж��ֹ淶�������淶�е�������ʽ������ͬ���е���ECCУ���룬�е�û��ECCУ���룬�����ECCУ�������ν��C3���룬�ɼ�������ÿ��CD���̹�߱���
�ϸ��˵��������ECCУ�鲢����C3���룬���DZ���ΪRSPC��Reed-Solomon Product-like Code������-�����ų˻����룩���롣ע�⣬CIRC�Ǹ�ÿһ֡����У��ı��룬��RSPC�Ǹ�������������У��ı��룬���߲�Ҫ���������ǿ����������⣺ÿ����������RSPC���롪���ֳ�98��֡����ÿ��֡�ٽ���CIRC���롪���������� ��¼���ݡ�
��֧��CD-ROM/-R/-RW���������У�Ҳ��������Ӧ��RSPC������������RSPC�Ĵ��ڣ���˼�ʹ��C2�����г�����E32�������п�����RSPC��������н�����������Ҳ��ΪʲôCD-ROM��Mode 1��Mode 2-Form 1������Լ�������ݴ洢��������ԭ��֤�����ļ���ȷ��Զ�ȱ�֤�������ݵ�ȷ�Ը���Ҫ���������ͨ��CD-Audio���Ż�������RSPC��������Decoder����
 ���������� 11011402011520��
���������� 11011402011520��